
A ten-minute talk about my research
I just had a talk proposal accepted to the student short talk session at POPL, which will be in Rome next week. They’re not messing around when they say “short” – the talk slots are only ten minutes long. As practice for my talk, then, here’s an overview of my research for the short on time. (For the even more time-pressed, I also have an even shorter talk that serves as a sort of abstract for this one.)
To be honest, this is still not quite short enough for a ten-minute slot. I’m sad that I’ll have to cut more material – I’ve already had to leave out some aspects of the work that I think are cool. So, please ask questions, and I’ll do my best to answer them either in comments or in a future post. Thanks! And, if you’re planning to be at POPL, I’d love to chat then, too – I’ll be speaking third in the student session on the 25th.
OK – start the clock…now!
A lattice-based approach to deterministic parallelism
Hi! I’m going to give a quick overview of the work I’ve been doing recently on a new model for deterministic-by-construction parallel computation. All this is in collaboration with my advisor, Ryan Newton.
A nondeterministic program
To clarify what “deterministic-by-construction” means, let’s first look at an example of a nondeterministic program, written in a hypothetical parallel language.1
let _ = put l 3 in
let par v = get l
_ = put l 4
in v
What happens when we run this program? Well, on line 1, we have a memory location l that we write 3 into. (The underscore on the first line just means that we don’t care about binding the value of put l 3 to a variable; we’re just evaluating it for its effect.) Then we have a let par expression, which has two subexpressions that we evaluate in parallel: on line 2, we get the value currently in l and assign it to v, and on line 3, we write 4 into l (with the latter, again, being evaluated only for effect).
Finally, on line 4 we get to the body of the let par expression, which is just v, and the value of v ends up being the value of the entire program. Depending on whether get l or put l 4 runs first, that value might be either 3 or 4. So multiple runs of this program can produce different observable results, depending on the whims of the scheduler – in other words, this program is nondeterministic.
The purpose of a deterministic-by-construction programming model is to rule out programs like this from being written, or force them to behave deterministically. How can we change our hypothetical language to only allow deterministic programs?
Disallow multiple assignment?
A popular approach for enforcing determinism is to require that variables can only be assigned to once, giving us a so-called single-assignment language. Our program would be invalid because it tries to write to l twice.2
let _ = put l 3 in
let par v = get l
_ = put l 4 (* error -- attempt to write to l a second time *)
in v
This approach works in general. Single-assignment variables with blocking read semantics, often known as IVars, turn up in all kinds of deterministic parallel systems.
But the single-assignment rule seems rather heavy-handed: it rules out a number of programs that we’d like to permit. The simplest example is a program that tries to write the same value to an IVar twice:
let _ = put l 3 in
let par v = get l
_ = put l 3 (* error -- attempt to write to l a second time *)
in v
This program is deterministic – the value of v is always going to end up the same – but it would be ruled out by the single-assignment restriction.
As another example, consider the problem of filling in various parts of a data structure in parallel. Say that l contains a pair, and we’re writing to l twice, with each write filling in one component of the pair. (The notation (4, _) just means that the write only touches the first element of the pair; likewise, (_, 3) just touches the second element.)
let par _ = put l (4, _)
_ = put l (_, 3) (* error -- attempt to write to l a second time *)
in get l
We don’t try to read from l until both writes have completed, so we’re always going to read (4, 3). But single-assignment rules out this program, as well. (In this particular case, we could fake it by using a distinct IVar for each component of the pair, but with more sophisticated data structures than this, we start running into situations where we can’t fake a solution with IVars.)
We’d like to generalize the single-assignment model to something that admits programs like these two, but retains determinism. We’ll come back to that in a moment.
Kahn process networks
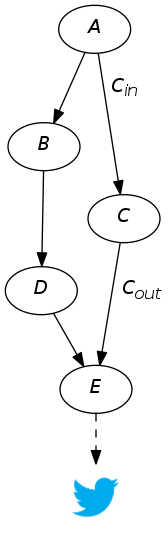
Consider a set of independent processors that can communicate with each other by sending and receiving data along input and output lines. How can such a system remain deterministic, with data flying all over the place and no restrictions on timing?
Let’s look at an example. Suppose that we have processors A, B, C, and so on, and that C has just one input and one output line, so we can name those lines Cin and Cout, respectively. We’ll call the sequence of values that have been sent along a line the history of the line; for instance, if A sends 3 along line Cin, followed by 0 and then 5, then Cin’s history so far is (to coin some notation) [3, 0, 5]. We’ll suppose that C does some computation on its input, then sends the result along Cout to E, which, whenever it receives something, posts it to Twitter.
Note that histories have a partial order – [3] comes before [3, 0], which comes before [3, 0, 5]. If I hand you two histories, it’s easy to check what their order is, if any – just check if one is a prefix of the other.
Each of our processors can be thought of as computing a function from the history of its input lines to the history of its output lines. But there’s an important restriction on the functions being computed: they have to preserve the “prefix-of” order of histories. For example, since [3] is a prefix of [3, 0], then whatever C spits out when given the history [3] must be a prefix of what C spits out when given [3, 0]. In other words, C computes a function that’s monotonic with respect to the prefix-of order.
What we gain from monotonicity
It would be unfortunate if C had to wait for A to produce all the numbers it was going to produce, then go through and do its thing on all of them, and finally for E to tweet all of them. We’d prefer that the work be pipelined.
Fortunately, the fact that C is monotonic makes pipelining trivial. When E receives something, say, 6, along Cout, monotonicity ensures that Cout’s current history of [6] is a prefix of the history that Cout will eventually have.3 So E doesn’t have to wait around to receive all the input (which, after all, might be an infinite stream); it can go ahead and tweet that 6 immediately, without waiting for the rest. Since monotonicity makes pipelining safe, we can get multiple processors going at once.
Moreover, consider what would happen if C computed a non-monotonic function, such as, for instance, the parity of Cin’s history length.4 Suppose Cin’s history is [3] at the moment C happens to run. That’s a history of length 1, and 1 is an odd number, so C sends a 1 to E. But if the scheduler decided to wait a little longer to let C run, Cin’s history might be [3, 0], and C would send 0 to E. E’s legions of eager Twitter followers would observe different outputs depending on what the scheduler felt like doing. This is an example of the kind of unintentional nondeterminism that monotonicity prevents.
The monotonicity of the functions computed by C and the other processors in the system makes parallelism possible and makes nondeterminism impossible. In fact, our network of processors is an example of a Kahn process network, or KPN, which is a classic model of deterministic parallel computation.
Back to single-assignment
If monotonicity is really so foundational to deterministic parallelism, then it should turn up in the single-assignment model as well as the KPN model. As it turns out, it does! For the sake of example, consider a not-particularly-exciting single-assignment program:
let _ = put l1 4 in
let par _ = put l2 3
_ = put l3 5
in get l2
As this program runs, the memory store grows: first we put 4 in location l1, and then, in some order, 3 in l2 and 5 in l3. At the end of the program, we can represent the store as (again, making up notation) a set of bindings: { l1 -> 4, l2 -> 3, l3 -> 5 }.
Because of the let par, the writes to l2 and l3 happen in arbitrary order. If the write to l2 happens first, we go from having the store { l1 -> 4 } to the store { l1 -> 4, l2 -> 3 }, and the former is a subset of the latter.
But if the write to l2 comes after the write to l3, then writing l2 takes us from { l1 -> 4, l3 -> 5 } to { l1 -> 4, l3 -> 5, l2 -> 3 }. Again, the former is a subset of the latter. In other words, the subset ordering of the stores { l1 -> 4 } and { l1 -> 4, l2 -> 3 } is preserved by applying the put l3 5 operation to both of them. Because put behaves monotonically with respect to the subset ordering, the order in which l2 and l3 are written doesn’t matter.
So monotonicity underpins the single-assignment model as well. But here’s my claim: the subset ordering is only one possible store ordering that we could choose to preserve, and it’s not a particularly flexible one – it doesn’t give us any way to talk about the order on stores based on the values in them.
Generalizing our notion of monotonicity
So, in our model, we do something more general: we define the order on stores in terms of a user-specified partially ordered set. The elements of this user-specified set are all the possible values that a store location can take on.
Under this model, multiple writes to a single store location are possible, as long as they’re monotonically increasing with respect to the user-specified order. In fact, that property is enforced by the language. We change the semantics of put to say that a write to a location is the least upper bound of the new value and the location’s current value. This means that if someone tries to write something to l that’s less than l’s current value, then l simply stays unchanged.
The single-assignment model that we already knew to be deterministic turns out to be a special case of this more general deterministic model. Since our variables that allow multiple monotonic writes are a generalization of IVars, we call them LVars, for “lattice variables”.5
Threshold reads
For the generalization from IVars to LVars to be safe, there’s one other important change we have to make. After all, if the user-specified set were, say, the natural numbers with the usual less-than-or-equal-to ordering, then our original nondeterministic program, with its write of 3 followed by a write of 4, would still be allowed.
The usual approach to enforcing determinism here would be to restrict when reads can happen. Our approach, instead, is to leverage the user-specified order again. We alter the semantics of get to restrict what can be read, using what we call threshold reads.
A threshold read is a read that blocks until the location it’s trying to read from has reached a value that is greater than or equal to a given “threshold value”.6 The threshold value is provided as a second argument to get. When the threshold is reached, the read will unblock, returning the threshold value.
let _ = put l 3 in
let par v = get l 4
_ = put l 4
in v (* Deterministic! *)
Here we’ve tweaked the call to get in our original program to take the threshold value 4. Now, v will always be 4 regardless of the order in which the two parallel subexpressions are evaluated. Moreover, if we had written get l 5, then the program would deterministically block forever.
Also, the two deterministic programs we looked at that were ruled out by the single-assignment model are perfectly fine under this model, with some tweaking to account for threshold reads. Any program in which we write the same value to an LVar multiple times Just Works now, because every value is less than or equal to itself. And for the pair example to work, we just need to specify an appropriate ordering on pairs.
Monotonically increasing writes + threshold reads = deterministic parallelism
To conclude, what we’ve done is generalize from single writes to monotonically increasing writes, and when we combine those monotonically increasing writes with threshold reads, we can maintain both parallelism and determinism. The resulting model is general enough to subsume the existing single-assignment model.
If you want to know more, there’s a lot more detail to be found in our tech report, including the semantics of a small LVar-based language and a proof of determinism for it. I think the determinism proof is worth discussing in its own right, and I’ll have more to say about that in future posts. In the tech report, we also discuss how to tweak the system to allow a limited form of nondeterminism that admits failures, but never wrong answers. And finally, you can find a Redex model of our language on GitHub.
-
Please forgive the awkward syntax highlighting in the code examples. I arbitrarily picked the OCaml highlighter so that we’d have at least some highlighting for our hypothetical language. ↩
-
We could enforce this single-assignment property at compile time – with a substructural type system, say – and programs that try to do multiple assignment would be rejected by the compiler; alternatively, we could have a run-time check, and the second attempt to assign to
lwould always raise a run-time error. Either way, we would have a deterministic model. ↩ -
[6, 1, 120], obviously! ↩ -
Thanks to Sam Rebelsky for suggesting this example. ↩
-
Actually, “lattice” is a bit of a misnomer: the user-specified set just needs to be a join-semilattice, which is a partially ordered set in which every two elements have a least upper bound. We need this to be the case because the semantics of both
putandgetinvolve taking the least upper bounds of store values. ↩ -
This restriction on
getis not as draconian as it seems: in general, rather than specifying only one threshold value, the programmer can specify a set of threshold values. However, the set has to be pairwise incompatible, which means that for any two distinct values in the set, their least upper bound has to be ⊤. The value in the location being read might then eventually become greater than or equal to any one element of the threshold set, at which point the call togetwill unblock and return that single element. ↩
Comments