
Consistency in Cassandra
by Natasha Mittal ⋅ edited by Devashish Purandare and Lindsey Kuper
Introduction
Today, popular NoSQL databases like Cassandra, MongoDB or HBase claim to provide eventual consistency and offer mechanisms to tune consistency.
A consistency model is a contract between the distributed data store and its clients, in which if the clients agree to obey rules for ordering the read/write operations, the underlying data store will precisely specify the result of those operations. In the context of Cassandra, consistency “refers to how up-to-date and synchronized a row of Cassandra data is on all of its replicas”.
Under strong consistency, all operations are seen in the same order by all the nodes in the cluster; that is, there must be a global total ordering of all read and write operations. This introduces high latency, as a lot of synchronization is required which hampers availability and scalability. On the other hand, eventual consistency merely guarantees that if no updates are made to a given data item, eventually all replicas will converge and return the last updated value of the data item. It provides lower latency, as there is less synchronization overhead.
Cassandra’s tunable consistency is intended to give clients the flexibility to adjust consistency levels to meet application requirements. Cassandra provides different read and write consistency levels, and users can fine-tune these levels by explicitly modifying Cassandra’s configuration file. The consistency level associated with an operation determines the number of replicas in the cluster that must respond with an acknowledgment for that operation to succeed.
In this blog post, we will go over Cassandra’s consistency levels, Light Weight Transactions (LWTs) which provide serial consistency, some background on vector clocks, and the 2013 Jepsen analysis of Cassandra that revealed a number of consistency-related bugs.
Cassandra’s Model of Consistency
Let’s establish a few definitions before getting started:
- RF (Replication Factor): the number of copies of each data item
- R: the number of replicas that are contacted when a data object is accessed through a read operation (the read set)
- W: the number of replicas that need to acknowledge the receipt of the update before the update completes (the write set)
- QUORUM: sum_of_replication_factors/2 + 1, where sum_of_replication_factors = sum of all the replication factor settings for each data center
If R + W > RF, the write set and the read set always overlap, resulting in what the Cassandra documentation describes as “strong” consistency.
The right choices for RF, R and W in this model depend on the application for which the storage system is being used. In a write-intensive application, setting W=1 and R=RF can affect durability, as failures can result in conflicting writes. In read-intensive applications, setting W=RF and R=1 can affect the probability of the write succeeding. To provide strong consistency and fault tolerance for a balanced mix of reads and writes, one should ensure that these two properties hold:
- R + W > RF
- R = W = QUORUM
For example, a system with configuration RF=3, W=2, and R=2 provides strong consistency.
R + W <= RF is a weaker consistency model, where there is a possibility that the read and write set will not overlap and the system is vulnerable to reading from nodes that have not yet received updates that have already completed on other nodse.
Read Requests in Cassandra
As the Cassandra documentation explains, Cassandra can send three types of read requests to a replica: direct read requests, digest requests, and background read repair requests. A digest request returns only a hash of the data being read instead of the actual data. The purpose of a digest request is to allow quick comparisons of the contents of replicas: if the hashes disagree, then the actual data will disagree as well.
When reading, the coordinator node sends a direct read request to one replica, and a digest request to a number of replicas determined by the read consistency level specified by the client. If all replicas are not in sync, the coordinator chooses the data with the latest timestamp and sends the result back to the client. Meanwhile, a background read repair request is sent to out-of-date replicas to ensure that the requested data is made consistent on all replicas.
The following table shows some of the read consistency levels that Cassandra provides:
| Consistency Level | Usage |
|---|---|
| ALL | highest consistency and lowest availability |
| QUORUM | strong consistency with some level of failure |
| LOCAL_QUORUM | strong consistency which avoids inter-datacenter communication latency |
| ONE | lowest consistency and highest availability |
Write Requests in Cassandra
For writes to a row, the coordinator node sends a write request to all the replicas that comprise the write set for that particular row. As long as all the replicas are available, they will get the write request regardless of the write consistency level specified by the client. For a write operation to succeed, the number of replicas required to respond with an acknowledgement is determined by the write consistency level. So, if W = QUORUM and RF = 3, then write request will be sent to all three replicas, but an acknowledgment is expected from any two.
Here are some of the write consistency levels Cassandra provides:
| Consistency Level | Usage |
|---|---|
| ALL | highest consistency and lowest availability |
| EACH_QUORUM | strong consistency but write fails when a data center is down |
| QUORUM | strong consistency with some level of failure |
| LOCAL_QUORUM | strong consistency which avoids inter-datacenter communication latency |
| ONE | low consistency and high availability |
| ANY | lowest consistency and highest availability and guarantees that write will never fail |
Lightweight Transactions (LWT)
Applications like banking or airline reservations require operations to be appear to be performed at a single, instantaneous, global time. This is linearizable consistency, which is one of the strongest single-object consistency models. Cassandra provides linearizability via lightweight transactions (LWTs).
In the SQL-like Cassandra Query Language, LWTs are used for INSERT, UPDATE, and DELETE operations that are conditioned on an IF or IF NOT EXISTS condition, such as:
INSERT INTO account (transaction_date, customer_id, amount)
VALUES (2016-11-02, 356, 125.00)
IF NOT EXISTS
UPDATE account SET amount = 230.00
WHERE payment_date = 2016-11-02
AND customer_id = 356
IF amount = 125.00
To synchronize replica nodes for LWTs, Cassandra uses an implementation of the Paxos consensus protocol. There are four phases in this implementation of Paxos: prepare/promise, read/results, propose/accept and commit/ack. Thus, Cassandra makes four network round trips between the coordinator node and other replicas in the cluster to ensure linearizable execution, so performance is affected. In fact, the Cassandra documentation points out that “IF conditions will incur a non-negligible performance cost (internally, Paxos will be used) so this should be used sparingly.”
Prepare/promise is the most time-consuming phase of the Paxos algorithm. The leader node proposes a ballot number and sends it to all the replicas in the cluster. The replicas accept the proposal if the ballot number is the highest it has seen so far and sends back a promise message which includes the most recent proposal it has already received in advance.
If a majority of the nodes promise to accept the ballot number, the leader can then move on to the next phase of the protocol. But if a majority of the nodes sent an earlier proposal with their promise message, the leader must use that value.
If a leader node interrupts a previous leader node, then it must finish the previous leader’s proposal first and then proceed with its own proposal, thereby assuring the desired linearizable behavior. After the commit phase, the value written by LWT is visible to non-LWTs.
The following is a (slightly anonymized) example of a Paxos trace in Cassandra (taken from one of my own Cassandra logs from a system I worked on):
Parsing insert into users (username, password, email ) values ( ‘mick’, ’mick’, ’mick@gmail.com' ) if
not exists; [SharedPool-Worker-1] | 2013-05-12 10:32:12.112000 | 127.0.0.1 | 1125
Sending PAXOS_PREPARE message to /127.0.0.3 [MessagingService-Outgoing-/127.0.0.3] | 2016-08-22 12:38:44.141000
| 127.0.0.1 | 10414
Sending PAXOS_PREPARE message to /127.0.0.2 [MessagingService-Outgoing-/127.0.0.2] | 2013-05-12 12:38:44.144200
| 127.0.0.1 | 10908
Promising ballot fb282190-685c-11e6-71a2-e0d2d098d5d6 [SharedPool-Worker-1] | 2013-05-12 12:38:44.149000 |
127.0.0.3 | 4325
Promising ballot fb282190-685c-11e6-71a2-e0d2d098d5d6 [SharedPool-Worker-1] | 2013-05-12 12:38:52.147000 |
127.0.0.3 | 4325
Promising ballot fb282190-685c-11e6-71a2-e0d2d098d5d6 [SharedPool-Worker-3] | 2013-05-12 12:38:52.166000 |
127.0.0.1 | 35282
Accepting proposal Commit(fb282190-685c-11e6-71a2-e0d2d098d5d6, [lwts.users] key=mick columns=[[] | [email
password]]\n Row: EMPTY | email=mick@gmail.com, password=mick) [SharedPool-Worker-2] |
2013-05-12 12:38:52.199000 | 127.0.0.1 | 67804
There are two consistency levels associated with LWTs:
- SERIAL: where the Paxos consensus protocol will involve all the nodes across multiple data centers.
- LOCAL_SERIAL: where the Paxos consensus protocol will run on the local datacenter.
Jepsen
Jepsen is an open-source Clojure library, written by Kyle Kingsbury, designed to test the partition tolerance of distributed systems by fuzzing them with random operations. The results of these tests are analyzed to expose failure modes and to verify if the system violates any of the consistency properties it claims to have. The Jepsen project did an analysis of Cassandra in 2013.
As Joel Knighton explains in his talk about how the DataStax team uses Jepsen, a Jepsen test has three key properties:
- It is generative: relies on randomized testing to explore the state space of distributed systems
- It’s “black box”: observes the system at client boundaries (does not need any tracing framework or apply some code patch in the distributed system to run the test)
- It relies on invariants: it checks invariants from the recorded history of operations rather than runtime
Knighton’s talk also covers the Jepsen test data structure:
{:name ...| name of the results
:os ...| prepares the operating system
:db ...| configures/starts/stops the database being tested
:client ...| client protocol to interact with database
:generator ...| instructs on how to interact
:conductors{:nemesis ...} | interacts with the environment
:checker ...} | looks at and assesses the test run
Finally, Knighton’s talk discusses how a Jepsen test runs. As he explains, in Jepsen an orchestration node has one thread representing each client of the system being tested, and a thread for the nemesis, which is the Jepsen process that injects failures into the system as it runs. The orchestration node connects to several nodes on which the Cassandra cluster is running. Jepsen generates a stream of read and write operations for client threads and crash/corrupt/partition operations for the nemesis thread. The result is a history that shows which operations happened during the test and when. Operations in the history are expressed as windows that show when they began and ended. Finally, Jepsen runs a checker that can determine whether the history is valid according to some metric of correctness. The checker can also produce an artifact to help explain performance characteristics, such as the latency of operations.
Jepsen Analysis of Cassandra
Background: Vector Clocks
Vector clocks are a technique for determining whether pairs of events are causally related in a distributed system. Logical timestamps are generated for each event in the system, and their potential causality (i.e., their happens-before relationship) is determined by comparing those logical timestamps.
The timestamp for an event is a vector of numbers, with each number corresponding to a process. Each process knows its position in the vector. Each process assigns a timestamp to each event.
For a message send event, the entire vector associated with that event is sent along with the message payload. When the message is received by a process, the receiving process does the following:
- Increments the counter for the process’s position in the vector.
- Performs an element-by-element comparison of the received vector with the process’s timestamp vector, and sets the process’s timestamp vector to the higher of the values:
for (i=0; i < num_elements; i++)
if (received[i] > system[i])
system[i] = received[i];
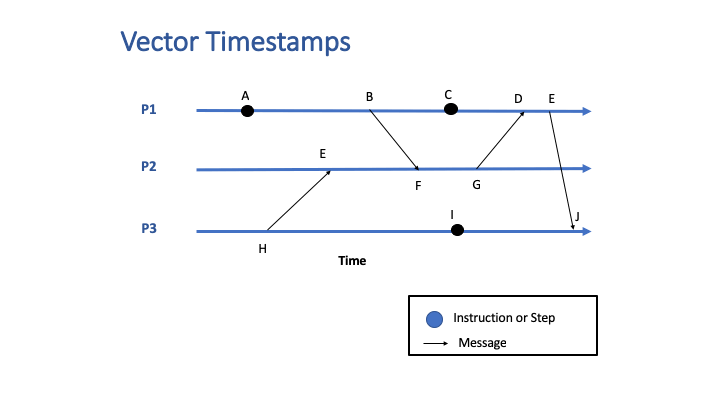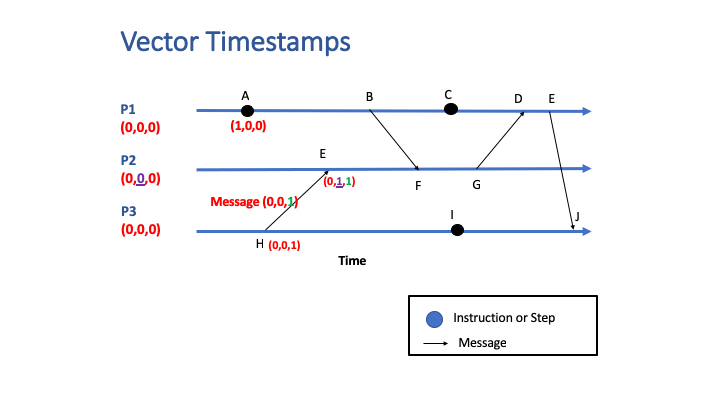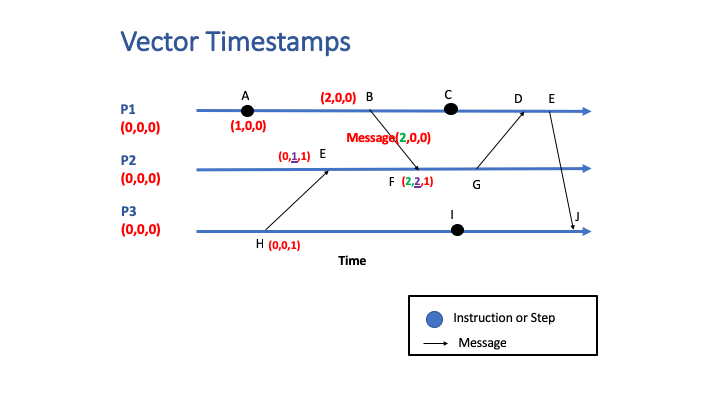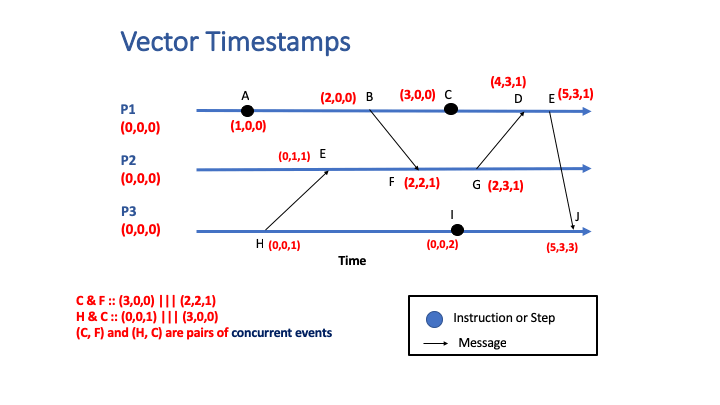
To determine if two events are concurrent, their vector timestamps are compared element-by-element.
- if each element of V1 timestamp <= each element of V2 timestamp, then V1 causally precedes V2, or
- if each element of V2 timestamp <= each element of V1 timestamp, then V2 causally precedes V1, or
- if neither of these conditions applies and some elements in V1 timestamp is greater than while others are less than the corresponding elements in V2 timestamp, then the events are concurrent.
The following animation shows an example of vector clocks in a system with three interacting processes:
Conflicting writes in Cassandra
Cassandra uses a last-write-wins (LWW) policy to resolve write conflicts and does not implement vector clocks “for performance reasons”. In this case, if a client A writes x=1, and another client B writes x=2, it is possible that the final value of x can be 1 or 2 depending upon which write comes second (the one with the most recent timestamp).
In order to avoid this problem, Cassandra uses the concept of immutable data. For every update operation for a particular column, a <value,timestamp> pair is added. For example, for a particular column called name, one might have a series of updates, as follows:
name
Mick, 2017-11-23 12:11:23
Micky, 2017-11-24 17:13:45
Micky Lawson, 2017-12-02 09:34:09
When a client makes a read request, a client-specific merge function is applied to all the column values and the desired result is obtained. In the case of equal timestamps (i.e., a tie), the lexicographically greater value is chosen.
For this to happen, two timestamps need to collide, and it would seem to be a rare possibility that two writes would get exactly the same microsecond-resolution timestamp. However, the Jepsen analysis of Cassandra tested this by repeatedly changing a column value and found that 1 row is corrupted per 250 transactions.
1000 total
399 acknowledged
397 survivors
4 acknowledged writes lost! //writes lost means corrupt data
This is happening because in Cassandra, the time resolution is in milliseconds, not microseconds. The probability of writes conflicting is much higher for millisecond resolution, resulting in much corrupted data.
Session consistency
Since Cassandra uses a last-write-wins policy, the writes are ordered by wall-clock timestamps. One might expect that the “Read Your Writes” and “Monotonic Reads” session guarantees would hold. However, the Jepsen tests of Cassandra introduce clock drifts due to which system clocks are unsynchronized, and the session guarantees no longer hold.
Another issue arises in the event of a leap second, which is “a one-second adjustment that is occasionally applied to civil time Coordinated Universal Time (UTC) to keep it close to the mean solar time at Greenwich, in spite of the Earth’s rotation slowdown and irregularities”. Linux kernel systems handle leap seconds by taking a one-second backward jump. When that happens, the following situation can arise in Cassandra, as Kyle Kingsbury explains:
Say a client writes w1 just prior to a leap second, then writes w2 just after the leap second. Session consistency demands that any subsequent read will see w2–but since w2 has a lower timestamp than w1, Cassandra immediately ignores w2 on any nodes where w1 is visible.
Since system clocks are not monotonic, timestamps alone cannot be used for global total ordering of operations across all the data centers.
Having worked extensively with Cassandra as a backend developer, I can say that these issues are prominent, and occur frequently during the copious amounts of transaction processing. This has forced enterprises to introduce hacks at the application level, thereby increasing complexity and making the application code lengthy.
Bugs that Jepsen analysis found in Cassandra
The Jepsen analysis of Cassandra found numerous issues that challenged Cassandra’s claim to offer linearizability via LWTs. Here I’ll highlight two specific bugs.
WriteTimeoutException when LWT concurrency level = QUORUM
As explained in Cassandra bug 9328 during high contention, the coordinator node “loses track” of whether the value it submitted to Paxos has been applied or not. For instance, in a banking application, the following situation could occur:
Thread 1: Reads account_balance=$0.
Thread 1: Updates account_balance=$0+$100=$100 successfully, but still receives WriteTimeoutException.
Thread 2: Reads account_balance=$100.
Thread 2: Updates account_balance=$100+500=$600 successfully with no WriteTimeoutException.
Thread 1: Tries again and reads account_balance=$600, which is greater than its previous update.
In this case, thread 1 cannot clearly identify whether its update failed or succeeded. It might assume that it failed and try again and add another $100 to the balance.
Incorrect implementation of Paxos
In Paxos, the leader node proposes the highest-number ballot that has been accepted by the nodes. In case no node responds back with a value, the leader then proposes its own value.
But Cassandra’s implementation of Paxos had a bug in which a value already accepted by some nodes could be ignored. As discussed in Cassandra bug 6012, the result is a system that “can mistakenly accept two different values for the same round.”
Since the first analysis of Cassandra by Jepsen in 2013, the DataStax team has adapted Jepsen and further extended it by incorporating new tests to break the new versions of Cassandra, and this has helped to identify critical bugs in the implementation.