
Some example MVar, IVar, and LVar programs in Haskell
In the writing and speaking I’ve done about LVars, I’ve done my best to show a lot of example code. For the most part, though, the examples have been written in a toy language created specifically for the purpose of discussing the LVars work.
For some people, this approach is fine. Others, however, find it less than satisfying. So, let’s see what it’s like to use LVars in a real language! If you’d like to run the examples yourself, all of the code from this post, plus some scaffolding for running it, is available on GitHub.
Also, an announcement: I’m going to be giving a talk about my work on LVars tomorrow, September 23, at FHPC. If you’re interested in this stuff and you’re here in Boston for ICFP and affiliated events, please come to my talk!
Nondeterminism with MVars
Since LVars are a mechanism for ensuring that programs behave deterministically, let’s start by writing an intentionally nondeterministic parallel program, to see what we’re up against.
A number of programming languages and libraries support some notion of an MVar: a shared mutable cell that can be used for communication among threads. In Haskell, the Control.Concurrent library provides an MVar data type. There are two fundamental things we can do with an MVar: write to it, using the putMVar operation, and read from it, using takeMVar.
putMVar and takeMVar are both blocking operations; putMVar will block if the MVar already contains a value, and takeMVar will block if it’s empty. However, reading with takeMVar also has the side effect of emptying the MVar, leaving it available to be written to again. Therefore MVars are appropriate for implementing higher-level synchronization abstractions. But we can also use them to write nondeterministic programs like this one:
import Control.Concurrent
p :: IO Int
p = do
num <- newEmptyMVar
forkIO $ putMVar num 3
forkIO $ putMVar num 4
takeMVar num
main = do
v <- p
putStr $ show v
Here, two putMVar operations race to write different values to num. What do the contents of num end up being? Running this program in parallel (with -N2) on my laptop, the answer seems to be “usually 4, but occasionally 3”:
$ make data-race-example
ghc -O2 data-race-example.hs -rtsopts -threaded
[1 of 1] Compiling Main ( data-race-example.hs, data-race-example.o )
Linking data-race-example ...
while true; do ./data-race-example +RTS -N2; done
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444434444444444444444444444444444434444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444344444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
4444444444^C
You get the idea. This an example of what we don’t want, so let’s look at what we can do about it. First, we’ll consider a traditional approach to enforcing determinism.
Enforcing determinism with IVars
Like an MVar, an IVar is a shared location that’s either empty or full and that can be read and written by multiple threads. Unlike an MVar, though, an IVar can only be written to once, and never again thereafter. (The “I” is for immutable.) IVar reads are blocking; if we try to read the contents of an empty IVar, our read will block until someone else writes something to it.
We can revise the above program to use an IVar instead of an MVar for num with the help of the IVar data type provided by Haskell’s monad-par library. The Control.Monad.Par module provides new, put, and get operations that respectively create, write to, and read from IVars. Note that the parallel computation now takes place inside the Par monad, and we only have to write fork instead of forkIO.
import Control.Monad.Par
p :: Par Int
p = do
num <- new
fork $ put num 3
fork $ put num 4
get num
main = do
putStr $ show $ runPar $ p
Because this program tries to write to num twice, it will deterministically raise an error at run-time. (Importantly, runPar requires all the forked threads to finish running before the program can end; otherwise, we’d have just been able to ignore one of the puts, leading to nondeterminism.) Here’s what we get when we try to run the program:
$ make ivar-example
ghc -O2 ivar-example.hs -rtsopts -threaded
[1 of 1] Compiling Main ( ivar-example.hs, ivar-example.o )
Linking ivar-example ...
./ivar-example +RTS -N2
ivar-example: multiple put
ivar-example: thread blocked indefinitely in an MVar operation
The “thread blocked indefinitely in an MVar operation” error message appears because, under the hood, runPar is implemented using MVars. (Parallelism business in the front; concurrency party in the back.)
A deterministic program that the single-write restriction rules out
The single-write restriction on IVars (when coupled with the blocking behavior of get) prevents us from writing programs that exhibit a certain kind of nondeterminism, which is great. Unfortunately, IVars also prevent us from writing certain deterministic programs that we might like to be able to write. As a simple example, let’s revise the above program so that, instead of trying to write different values into an IVar from two different threads, it tries to write the same value from two different threads:
import Control.Monad.Par
p :: Par Int
p = do
num <- new
fork $ put num 4
fork $ put num 4
get num
main = do
putStr $ show $ runPar $ p
Instead of threads racing to write 3 and 4, we now have threads that are racing to write 4 and 4. It’s clear that v should deterministically end up as 4, regardless of who wins the race. But because of the single-write restriction on IVars, this program raises a run-time error, just as the previous one did:
$ make repeated-write-ivar
ghc -O2 repeated-write-ivar.hs -rtsopts -threaded
[1 of 1] Compiling Main ( repeated-write-ivar.hs, repeated-write-ivar.o )
Linking repeated-write-ivar ...
./repeated-write-ivar +RTS -N2
repeated-write-ivar: multiple put
repeated-write-ivar: thread blocked indefinitely in an MVar operation
Can we do better than this? We want something that retains the determinism of IVars, but is flexible enough to allow us to write deterministic programs like the above. This is where LVars come in.
LVars: determinism and multiple monotonic writes
Like MVars and IVars, LVars are locations that can be shared among multiple threads. Like IVars, they ensure determinism: a program in which all communication takes place over LVars (and in which there are no other side effects) is guaranteed to evaluate to the same value every time.
Unlike IVars, though, LVars allow multiple monotonic writes. That is, it’s fine to write to an LVar multiple times, with the caveat that the LVar’s contents must stay the same or grow bigger with each write.
What does it mean for the contents of an LVar to “grow bigger”? It depends! For any given LVar, there’s a set of states that the LVar might take on. The key idea of LVars is that these states have an ordering, and the LVar can only change over time in a way that preserves that ordering. This is guaranteed to be the case because the put operation updates the contents of the LVar to the least upper bound of the previous value and the new value.
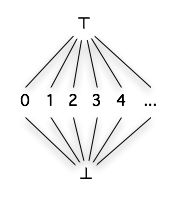
In fact, this notion of order-preserving updates was there all along with ordinary IVars! It’s just that, for IVars, the ordering on states is extremely boring. There are only two states of interest, “empty” and “full”, where empty is less than full, and once we’re full, we can never go back to empty.
Consider a lattice representing the states that a natural-number-valued IVar can take on. The bottom element of the lattice, ⊥, represents the “empty” state of the IVar. The elements 0, 1, 2, 3, 4, and so on represent each of the possible “full” states. Finally, the top element, ⊤, represents the error state that results from a multiple put. Notice that the least upper bound of any two different “full” states (say, 3 and 4, for instance) is ⊤, indicating that if we tried to write both of those values, we’d get an error, as we’d expect. But the least upper bound of any element and itself is merely that element, of course, and this seems to match our intuition that repeated writes of the same value to an IVar ought to be fine with regard to determinism.
So, my claim is that the lattice-based semantics of LVars is a natural fit for IVars; in fact, IVars turn out to be a special case of LVars. The only difference in interface between the IVars we’re used to using and IVars implemented using this lattice-based semantics is that the latter support repeated writes of the same value without exploding at run-time.
Of course, we can also have LVars whose states correspond to more interesting lattices. For now, though, we’ll stick with this simple case.
LVars in Haskell
Recently, Aaron Turon, Ryan Newton, and I have been working on LVish, a Haskell library for programming with LVars. We’re planning to make a release of LVish soon, but if you have GHC 7.6.3 installed and you’d like to be able to run the rest of the examples in this post yourself, you can download the source from GitHub and install it:
git clone git@github.com:iu-parfunc/lvars.git
cd lvars/haskell/lvish
cabal install
Update (October 3, 2013): We’ve released the LVish package on Hackage, so, although the above directions will still work, you should now be able to install the released version with cabal install lvish (perhaps following a cabal update). Enjoy!
Warning! This is research code! There are lots of bugs! The API will change! The documentation is incomplete! It will eat your laundry! And if you like your Haskell environment just fine the way it is, consider installing it sandboxed.
With that caveat out of the way, let’s write some code!
For any given program that we want to use LVars in, we’ll need to import two things:
-
The
Control.LVishmodule, which provides core functionality that’s not specific to any LVar; every LVish program will need to import this. -
The module(s) for the particular LVar(s) that we want to use. We’ll use
Data.LVar.IVarin our examples, but there’s a growing collection of other data structures to choose from, and you’re also free to implement your own.
Rewritten using LVish, our program looks like this:
{-# LANGUAGE DataKinds #-}
import Control.LVish
import Data.LVar.IVar
p :: Par Det s Int
p = do
num <- new
fork $ put num 4
fork $ put num 4
get num
main = do
putStr $ show $ runPar $ p
Aside from the two new imports, the main thing that’s changed is the type of p. It’s still a Par computation, but instead of Par Int, it’s now Par Det s Int. What do Det and s mean?
First of all, the Det type parameter refers to the computation’s determinism level, in this case Det for deterministic. This is necessary because it’s also possible to write LVish programs in that are quasi-deterministic, meaning deterministic modulo exceptions, in which case we’d use the QuasiDet determinism level. Quasi-determinism is the topic of our recent draft paper, and I’ll have more to say about it here on the blog eventually. For now, though, we can think of the Det parameter as giving us a degree of assurance that the computation is actually deterministic, since, with Det there, it would be a type error to use the parts of LVish that would introduce quasi-determinism. (It’s because of this Det parameter that our program now also needs the DataKinds extension to Haskell.)
Second, there’s the s type variable, which we can think of as standing for “session seal”. In ordinary Par programs where the type of runPar is Par a -> a, there’s nothing stopping us from returning an IVar from one call to runPar and passing it to another. As Simon Marlow writes in his excellent book Parallel and Concurrent Programming in Haskell, “This is a Very Bad Idea; don’t do it. The implementation of the Par monad assumes that IVars are created and used within the same runPar, and breaking this assumption could lead to a runtime error, deadlock, or worse.”
In LVish, on the other hand, the type of runPar is (forall s . Par Det s a) -> a. The universally quantified s ensures that an LVar can’t escape from inside the Par computation, although it comes at the price of having a mysterious s hanging out in the type of p. (This feature is orthogonal to anything having to do with LVars as such, but it’s a change that’s planned for the Par monad anyway, so we went with it in the LVish version of Par as well.)
Aside from the type of p and the addition of the DataKinds language extension, we haven’t had to change our code at all. Let’s see what happens when we run it now:
$ make repeated-write-lvar
ghc -O2 repeated-write-lvar.hs -rtsopts -threaded
[1 of 1] Compiling Main ( repeated-write-lvar.hs, repeated-write-lvar.o )
Linking repeated-write-lvar ...
while true; do ./repeated-write-lvar +RTS -N2; done
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
444444444444444444444444444444444444444444444444444444444444444444444444444444
4444444444444444444444444444444444444444444444444444444444444444444444444^C
And so on – instead of a “multiple put” error, we deterministically get 4, the answer we were hoping for.
Finally, let’s check to make sure that writing different values to an IVar still raises an error as it should. Switching back to 3 and 4 instead of 4 and 4, our code looks like this:
{-# LANGUAGE DataKinds #-}
import Control.LVish
import Data.LVar.IVar
p :: Par Det s Int
p = do
num <- new
fork $ put num 3
fork $ put num 4
get num
main = do
putStr $ show $ runPar $ p
And, when we run it, we get an error:
$ make repeated-write-lvar-wrong
ghc -O2 repeated-write-lvar-wrong.hs -rtsopts -threaded
[1 of 1] Compiling Main ( repeated-write-lvar-wrong.hs, repeated-write-lvar-wrong.o )
Linking repeated-write-lvar-wrong ...
./repeated-write-lvar-wrong +RTS -N2
repeated-write-lvar-wrong: Multiple puts to an IVar! (obj 19 was 18)
Now that I think about it, the wording of this error message isn’t great; we should probably have it say something like “Multiple differently-valued puts to an IVar!” (And the (obj 19 was 18) business should probably be behind a debug flag or something.) But, you get the idea; would-be nondeterministic programs like the above are forced to deterministically raise an error, just as they would with the traditional implementation of IVars.
How do we know that LVish programs are deterministic?
Of course, merely running a program once or a few hundred times and seeing that it behaves in the way we want doesn’t constitute proof that it will always behave the way we want. How do we know that the above programs are deterministic – that the first will always print 4, and that the second will always raise an error?
In the tech report that accompanies the paper I’m presenting at FHPC tomorrow, we give a proof of determinism for lambdaLVar, the core calculus on which the LVish library is based. Assuming that we trust that proof, the question becomes: is the LVish library a faithful implementation of lambdaLVar’s semantics?
To answer that question, we’ll need to, for instance, look at the code for the put operation and make sure that it actually computes the least upper bound with respect to the given lattice. In the case of Data.LVar.IVar, this isn’t so hard to verify informally, at least. For some other LVars, it might not be so easy. The burden of proof is on the data structure implementor to ensure that the put operation for a given LVar implementation is correct with respect to the specification.
If we were able to express the specifications of put and get in their types, then we would have no more work to do. Unfortunately, in Haskell there’s no obvious way to use the type system to ensure that, for instance, put computes least upper bound. For that, we probably need a more powerful dependent type system, and this is an interesting avenue for future work. (If you, dear reader, are interested in implementing LVars in, say, Agda or Idris, I’d love to talk to you about it sometime.)
Why should we care about being able to write the same thing twice?
We’ve seen that LVars make it possible to write the same value to an IVar multiple times. But why does that matter? When will we ever want to do that, except in contrived blog-post examples? To wrap up this post, I’ll try to give a possible use case for this feature.
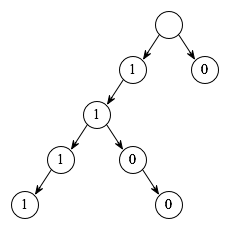
Consider a bitwise trie data structure into which we can insert strings of bits. Inserting a string involves iterating over each bit and inserting them one at a time, forming a chain of nodes from root to leaf, where each node represents a bit.
Suppose we wanted to implement a concurrent bitwise trie – one that allows deterministic concurrent insertions. Could we represent the trie using traditional IVars? It seems like a reasonable idea at first blush. In the trie’s initial, empty state, the root node could point to two empty IVars, one for each of the first two possible insertions, 1 and 0. Whenever we inserted a bit, it would fill an existing empty IVar, and that node could point to two empty IVars for its potential children.
How about concurrent insertions? Concurrently inserting the strings '0' and '1100' would work fine, since they don’t overlap at all. Indeed, any data structure built out of IVars will work fine in general, as long as writes never overlap.
But suppose that we want to concurrently insert two strings that happen to share a prefix – suppose, for instance, that one thread is trying to insert '1100' while another is trying to insert '1111'. Now we have a dilemma. If one thread writes into the topmost IVar for 1, but the other thread has gotten there first and done its insertion, we’ll raise a multiple-put error. So we need to check for emptiness before doing a write – but there’s no way to do so, since the only deterministic way to read from an IVar is to make a get call that will block until the IVar is full. So, each thread will have to block waiting for the other – even though the result of the two writes would be the same regardless of the order in which they occurred. If we were using LVars instead of IVars, then the two inserting threads could happily race to write their shared prefix, with no risk of nondeterminism, since they’d both be writing the same thing!
We’ve seen that the same value more than once is a special case of the multiple monotonic updates that LVars allow in general. In fact, rather than thinking of each node of our bitwise trie as an LVar, we could think of the entire bitwise trie as a single LVar whose contents grow monotonically with each insertion. Since LVars allow multiple monotonic updates, they can handle overlapping but non-conflicting writes that have a deterministic result – or, in other words, a least upper bound other than ⊤. Therefore the meaning of “non-conflicting writes” depends entirely on the lattice we choose, and we can specialize it to the particular problem we have to solve.
Thanks for reading!
If there’s anything I can explain better, or if you encounter any issues with the example code in this post, let me know in the comments. Thanks, and see you at FHPC and ICFP!
Comments