
Talk at Sunday Assembly Silicon Valley: “What could go wrong?”

This month, I had the honor of giving a very personal talk about distributed computing systems at Sunday Assembly Silicon Valley, which had the theme of “Connected” for our August meeting. I’ve been an SASV member and volunteer for a long time, but this is the first time I’ve been the speaker.
This is not a research talk; it’s different from any talk I’ve ever given. This post is a pseudo-transcript of my talk. I’ve also posted the full set of slides, for those interested. A video recording of the assembly is up on YouTube, and the part that’s my talk starts at about 20:25 in the recording and lasts for about 15 minutes.1 (The slides don’t show up especially well on the video, though.)
LiveJournal
Thanks for the warm welcome. Hi, I’m Lindsey! We’re going to talk about distributed systems.
I’m going to warn you, though – this talk is a little bit different from the talk that I planned to give, but I sat down to write the talk yesterday and this is what came out, so I went with it.

Has anyone here seen the movie The Social Network? If you haven’t, I recommend it. The movie takes place twenty years ago, at the dawn of the twenty-first century, and it’s a dramatization of the early days of Facebook. It’s a good movie, very entertaining and gripping, with a screenplay by Aaron Sorkin. This is the amazing opening scene.
The movie almost certainly takes a lot of liberties with the truth. However, there was one part that felt so historically accurate to me that it actually made me gasp with recognition.
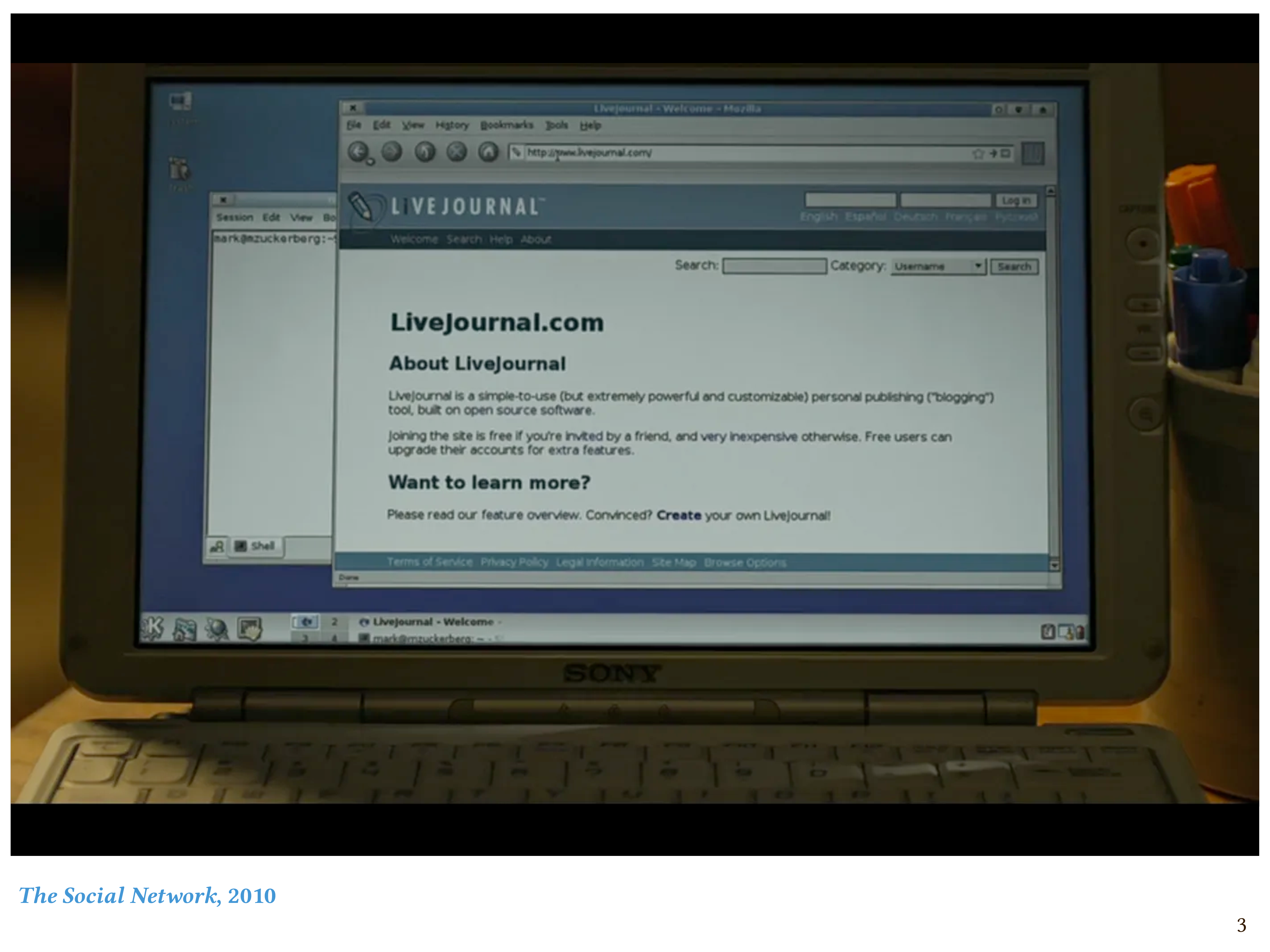
And it’s this one. After the opening scene, in which his girlfriend dumps him, the Mark Zuckerberg character goes home and sits down at his computer, in his dorm room. He’s a nerdy 20-year-old undergrad college student, and I can tell you from personal lived experience that what he does then is exactly what nerdy college students did in 2003 when they got home: he goes on LiveJournal. In particular, he writes hateful things about his now ex-girlfriend, but that’s not what I want to talk about.
What I want to talk about is LiveJournal. LiveJournal, or LJ for short, was a social networking website that predated the term “social networking”. People used it to write about what was going on in their lives, and in 2003 I used it every day. I was a nerdy 20-year-old college student living in the dorms, and that’s what we did. I got to know a lot of people on LiveJournal, including Alex, who is now my husband of twelve years. But I didn’t just use LiveJournal; I also worked for LiveJournal. I did technical support. Not for money, of course; I did it strictly as an unpaid volunteer.

As far as I know, there was only one technical support team member who was actually employed by LiveJournal; her name was Denise, and she’s one of my personal heroes. One of the many things Denise did was cultivate a community of dedicated people who did LiveJournal tech support, for free, as volunteers, because we wanted to. It’s hard for me to imagine people doing free tech support for fun at Facebook, or Twitter, or whatever they’re called now. I think the fact that we were willing – not only willing, but actually eager – to do this for LJ says something about how much LJ meant to us.
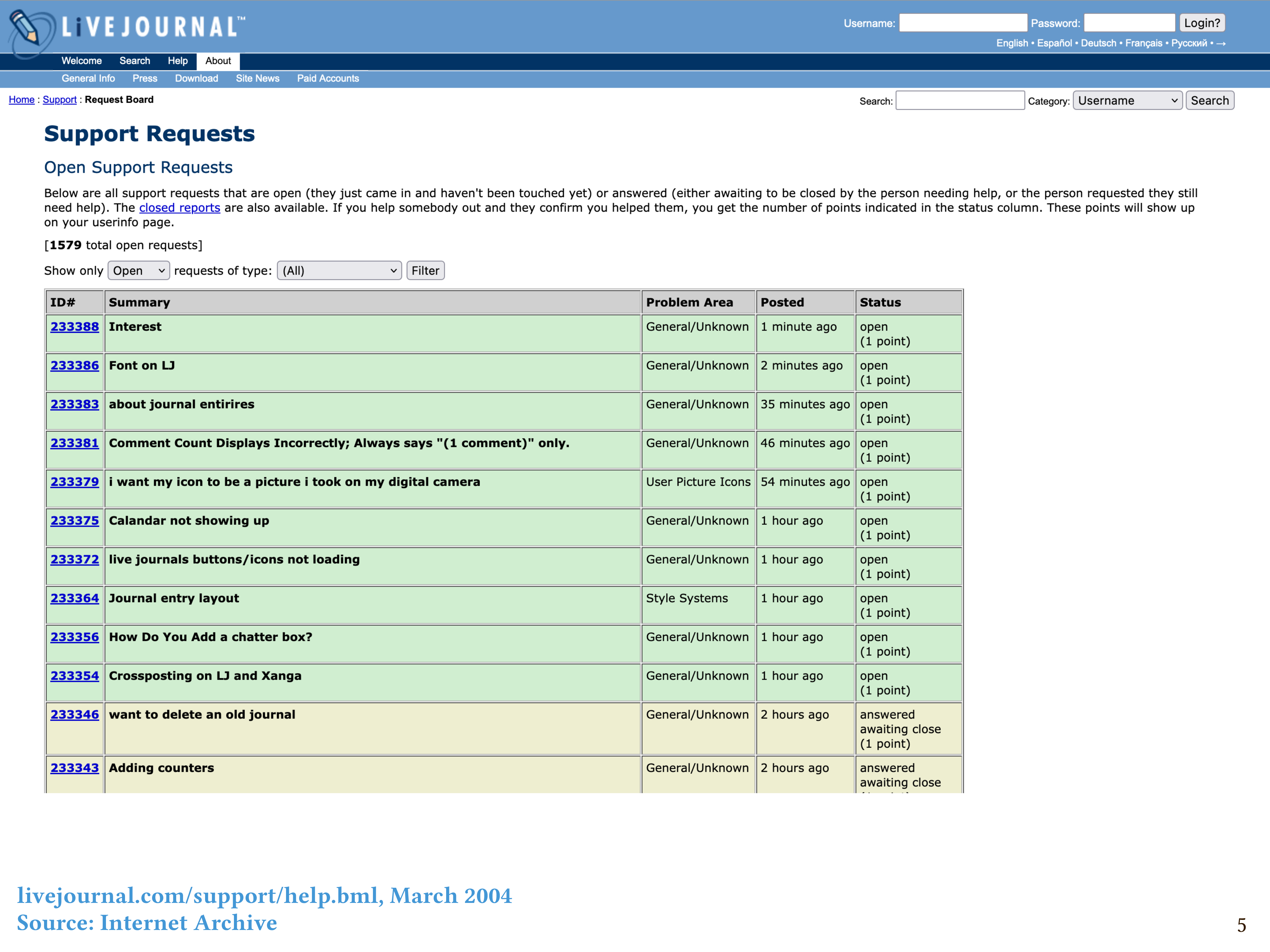
Here’s how it worked. When people had tech support questions – say, about how to customize the look of their journal – they would submit those questions using a form. Support volunteers would see a list of open questions, which looked like this – thank you to the Internet Archive for having an archived version of this web page from March 2004 – and we would post candidate answers to the questions. Another, higher-level support volunteer would then go in, see the submitted answers, and approve the best one, which would then be shown to the user. If your answer got approved, you would earn one point for answering the question, and you’d go onto a scoreboard. If the higher-level volunteer deemed none of the candidate answers good enough to approve, then the question would remain open, and the number of points it was worth would slowly increase as time went by. The hardest-to-answer questions would be worth ten points, and might require days of work on the part of a volunteer to answer properly.
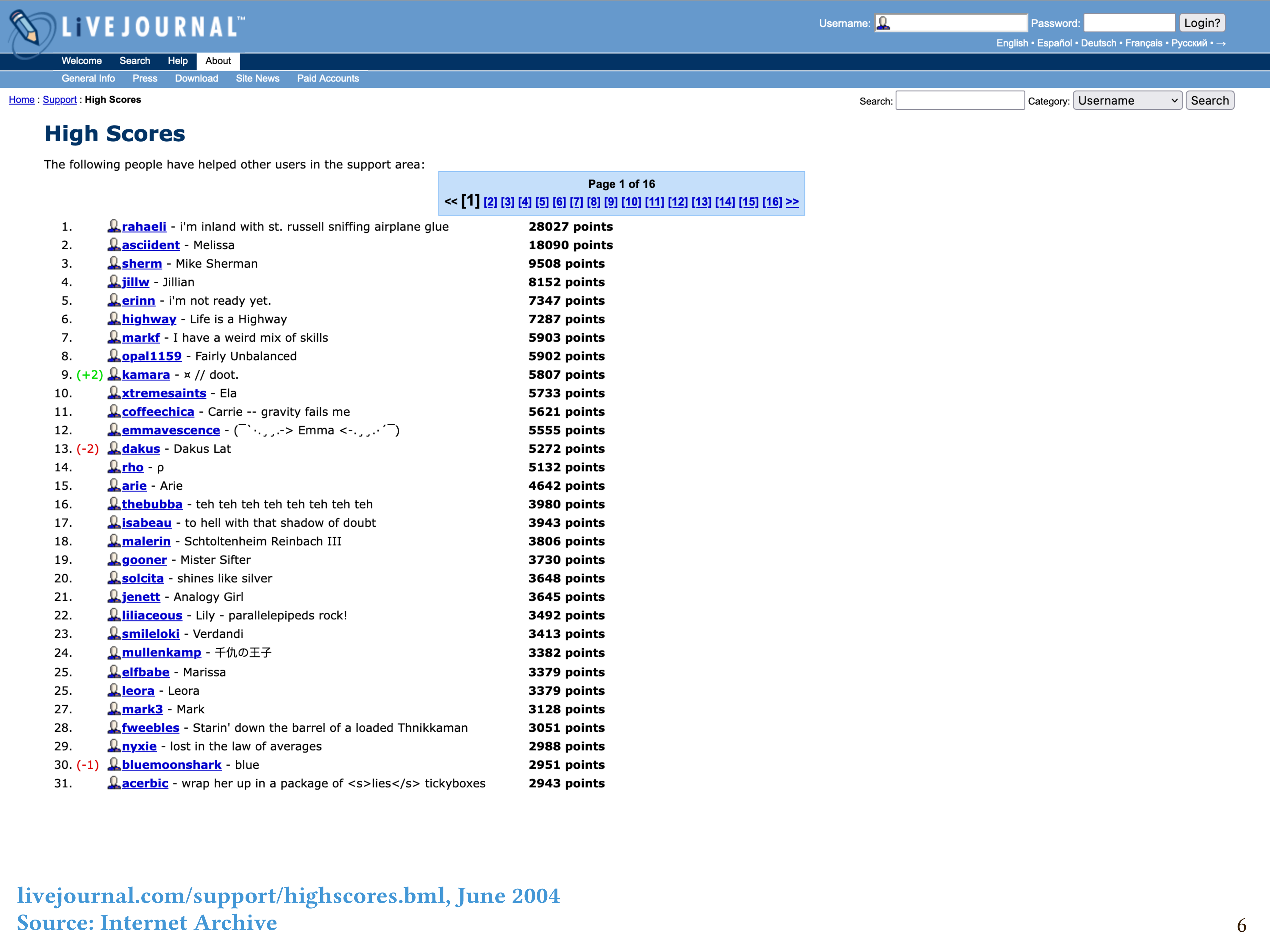
This is what the high scores page looked like in 2004. As you can see, the top people had thousands of points. But it might take a long time, and a lot of attempts, for a volunteer to earn even one support point. For one thing, it took a while to learn the norms of question answering. The support team aimed to answer users’ requests with tremendous grace and professionalism, even when the user was angry or their question was hard to understand. An answer that was even slightly unprofessional wouldn’t get approved. There were even detailed guides on how to answer support questions – again, these guides were written by volunteers! I was really proud when I earned my first support point.
There were also different categories of support requests. Sensitive requests, like stuff that had to do with harassment or abuse cases, would go to a dedicated team – I never dealt with those. Many users had questions about how to customize the look of their LiveJournal, and these customizations could get extremely sophisticated; some support team members specialized in answering those, and helping people debug their customizations. I liked answering those a lot; they were usually fun puzzles to solve, and that’s where most of my points came from.
And then there was the category of support request known as “General/Unknown”, or “gunk” for short. The “gunk” questions were those that didn’t fit anywhere else. They were all over the map, but fairly commonly, a “gunk” question was something like, “Why is the website not loading?” or “Why is my journal really slow to load?”
Now, unlike a lot of support volunteers, I was actually a computer science student. At least in principle, I was receiving professional training in how this stuff worked. And my training indeed served me well when I was helping people fix their broken style customizations on LiveJournal. I didn’t know everything, not by a long shot. But I knew how to narrow down a problem, how to use debugging tools, how to test things. A lot of users were grateful for my help on their support questions. I worked hard and moved up the scoreboard, over time earning more privileges in the support system.
But when it came to those support requests like “Why is the website so slow?” or “Why is my journal not loading?”, I felt completely useless. Nothing I had learned in school had prepared me to answer questions like that. I couldn’t help, and I was ashamed that I couldn’t help. When questions like that appeared on the support forum, I’d slink away and look for the ones I actually knew how to answer, because I had no visibility into the reasons why they might be having this problem. There was nothing useful I could say.
What is a distributed system?

Fast forward twenty years. It’s 2023. I’m a computer science professor now. Here’s a picture of me at work. I specialize in the subfield of computer science known as distributed systems.2
What exactly is a distributed system? I’ll start by giving a definition that was intended as a joke. But, as we’ll see, there’s more than a little bit of truth to this joke.
So there’s a guy named Leslie Lamport who is often considered the father of distributed systems. He currently works at Microsoft Research, and he’s had a really long and distinguished career. He won a Turing Award, which is like the Nobel Prize for computer science, and so on.

So this joke definition of distributed systems is due to Leslie Lamport, the guy who invented a lot of the stuff that I teach in my classes. Lamport said, “A distributed system is one in which the failure of a computer that you didn’t even know existed can render your own computer unusable.”
Now, this definition is obviously meant to be funny, but many a true word is spoken in jest. So let’s think a little bit about what it means. What does “failure” mean? What did Lamport mean by that?
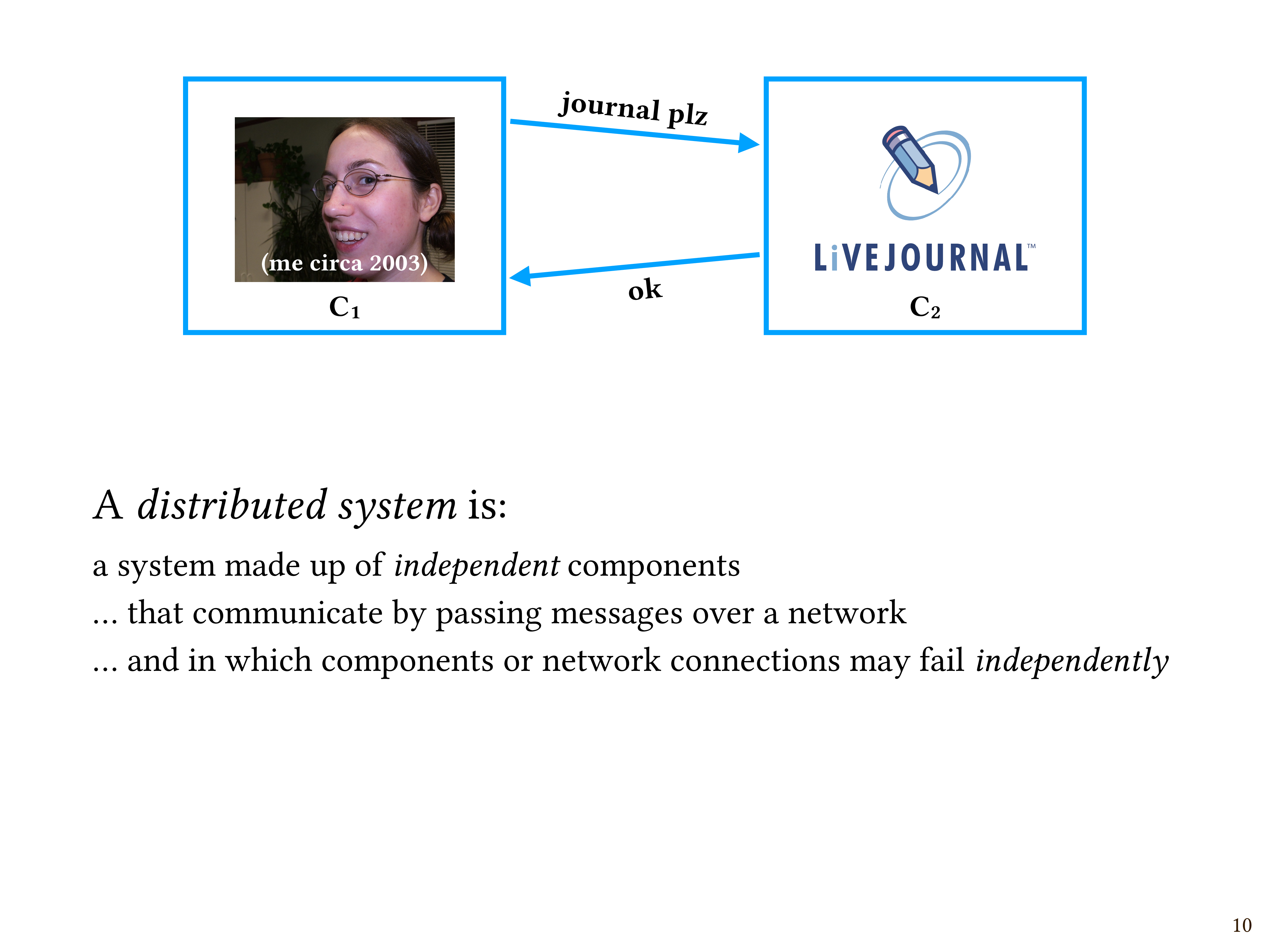
Let’s do a simple thought experiment. I’d say “suppose we have computers C1 and C2”, but that’s kind of boring, so let’s make it more interesting.

The box on the left, call it C1, is me in 2003. This is the best picture of me I could find from that era. I’m really proud of my new nose piercing. So, C1 is me.
C2 is LiveJournal. I’m sitting in my dorm room in 2003, and I want to access my journal on LiveJournal.com. My computer sends a message to their computer saying, “Journal, please!” And it responds, here you go! Here’s your journal.
What are some of the ways in which this very simple exchange of two messages could go wrong? What do you think?
(At this point in the talk, I took audience suggestions. The answers were good: “The message doesn’t arrive” or “The message arrives, but you don’t know it arrives.”)
Okay, let’s try to list some possibilities:
- The request from C1 to C2 to could get lost.
- The request from C1 to C2 could just be slow.
- C2 could crash.
- C2 could just be slow.
- The response from C2 to C1 could get lost.
- The response from C2 to C1 could just be slow.
So that’s at least six different ways in which this could go wrong. And there’s one that we haven’t even mentioned, which is that C2 could lie! Maybe it’s been compromised by an attacker somehow, maybe someone just messed up, but for whatever reason, it could behave in an arbitrary or malicious way! (This is what distributed systems people call Byzantine behavior.)
If I am C1, and I ask for my journal and I don’t get a response, do I have any way of knowing which of those seven failures occurred?
The answer is no, not really. In fact, in general, if you send a request to another component in a system and you don’t receive a response, it’s actually impossible (from within the system) to know why.
Now, you as a human, from outside the system, may be able to observe things that aren’t observable from within the system. Maybe you can look under your desk and see that the network cable came unplugged. You can look out your window and see that a backhoe took out a fiber optic cable. But from within the system, if you’re expecting a message but haven’t received it yet, it’s impossible to know whether it’s still on its way but just delayed, or whether it’s never coming.
This brings us to a possibly more helpful definition of “distributed system”.
A distributed system is:
- a system made up of independent components
- that communicate by passing messages to one another over a network,
- and in which components or network connections may fail independently
This “independently” thing is important: it means that the whole system doesn’t succeed or fail as a unit, but rather that at any given time, some parts might be working, while other parts might be broken.
People who work with distributed systems have to contend with, and plan for, constant partial failure.
Uncertainty
So, coming back to our LiveJournal example, what actually happens in real life? Suppose I make a request and I never get a response, possibly because the response got lost on the way back. How do real computer systems actually deal with this?

Typically, they use something called “timeouts”. C1 will have a timeout, which is a policy that says, after some specified amount of time – which I measure locally according to my own clock – if there’s no response to my request after that specified amount of time, then assume failure, and possibly try again, or maybe give up and kick the problem to the user for them to deal with.
But why might it be wrong to assume failure when a request times out? Why might that be a bad idea? Certainly, it might be wrong because the response could just be slow, right? But is there anything that might be even worse? What do you think?
(I paused again at this point for audience input, and there was another perfect answer: “What if you’re trying to buy something?”)
Exactly. What if your request had some sort of side effect? Maybe instead of just me reading my LiveJournal in 2003, what if we’re talking about someone voting in an election in 2023? Maybe the request is “count my vote, please”.
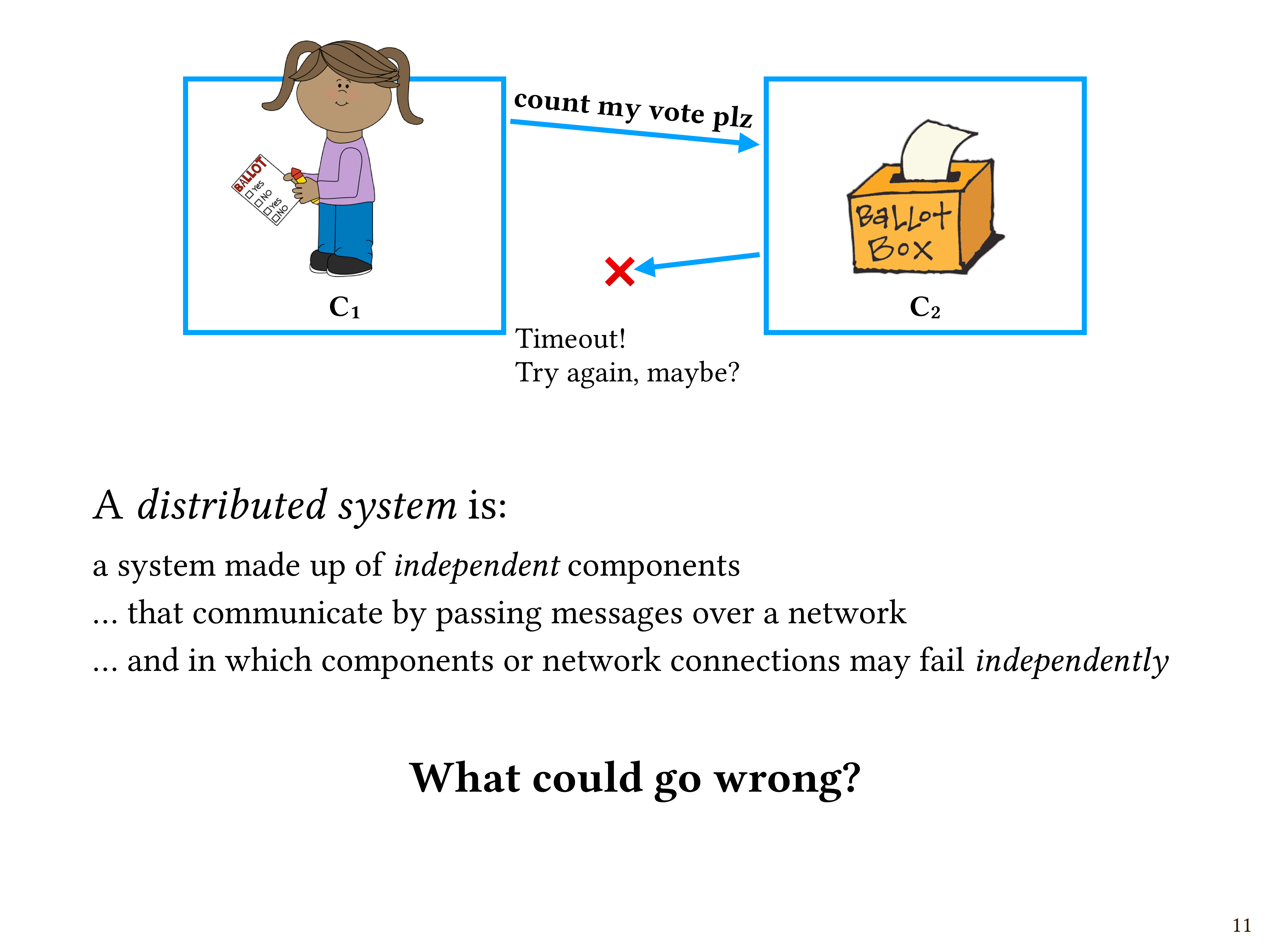
Let’s say the request gets to C2, and C2 carries out the request and sends an acknowledgment. But then the acknowledgement gets lost. So, if you’re C1 and you don’t get the acknowledgement, maybe you time out. You’re sitting here waiting, thinking, “I never heard back. Maybe the thing I wanted never happened.” Meanwhile, maybe it actually did happen. It would be wrong to assume that your vote wasn’t counted, but it would also be wrong to assume that it was.
This uncertainty is a fundamental characteristic of distributed systems. And people who build distributed systems need to always be asking themselves, “What could go wrong?” If you’re good at catastrophizing, you might be good at distributed systems.
So if I could go back in time and talk to that twenty-year-old kid in 2003 who was ashamed about not knowing how to answer LiveJournal support questions, she probably wouldn’t listen to me, but what I would say is: You don’t have anything to be ashamed of, because questions like “Why is my journal not loading?” are literally impossible to answer from where you’re sitting. Uncertainty is part of the nature of distributed systems, and 2003-me should not have felt bad that she had no answer to those questions other than “Try again later, I guess?”. My hope is that the students who take my distributed systems class can come away from it feeling less ashamed than I did back then.
In this 15-minute talk, I didn’t have time to get into what we can actually do to try to grapple with this uncertainty. If you’re interested in that, one thing I recommend is watching the lectures for my undergraduate distributed systems class, which are all online; just search for my name on YouTube. Here’s a screenshot of my YouTube channel with some of my videos.
Thanks again for listening!
Comments