
Diversifying Consistency in Ceph
by Aldrin Montana · edited by Austen Barker and Lindsey Kuper
Introduction
In my previous post, we provided background and motivation for mixing consistency in a programmable storage system. In this post, we describe approaches to supporting a range of consistency options in the Ceph storage system to enable mixed-consistency, programmable storage on top of Ceph.
We will compare approaches to implementing a variety of consistency models by first looking at the implementation of PROAR, a recently proposed replication strategy for Ceph that trades strong consistency for lower write latency. We will also consider other approaches to implementing eventual consistency in Ceph. Finally, we’ll consider implementing [“bolt-on” causal consistency][bolt-on-paper] on top of Ceph, which requires that the underlying datastore support eventual consistency.
Replication and Data Placement in Ceph
To understand how Ceph might support weaker consistency models such as eventual consistency or causal consistency, we describe how the storage subsystem in Ceph, RADOS, manages persistent storage and replication. We also mention the role of Ceph’s CRUSH algorithm for determining data placement.
Storage in RADOS consists of four layers of abstraction. At the highest level are files or abstractions for applications to write and read data. The second layer maps files to data objects. Then, the third layer distributes (stripes) data objects across the storage cluster into placement groups (PGs) using a hash function. Each PG has a replication factor, which represents how many replicas a data object assigned to the PG will have. A PG is a logical entity, not a server, that can be likened to a horizontal shard in data management systems. At the lowest level of abstraction, object storage devices (OSDs) handle data persistence and replication.
The diagram below depicts an overview of the data placement in Ceph. OSDs are assigned to, or organized into, PGs. OSDs of the same PG cooperate to replicate data objects and exchange state, and do not communicate with OSDs associated with other PGs. The diagram below is based on descriptions in the RADOS and Ceph papers; for a slightly higher level of abstraction, see Figure 3 in the Ceph paper. The mapping of files to objects to PGs to OSDs is succinctly described in Section 5 of the Ceph paper. The organization of OSDs into a PG is calculated using the CRUSH (“controlled replication under scalable hashing”) algorithm, detailed in the CRUSH paper.
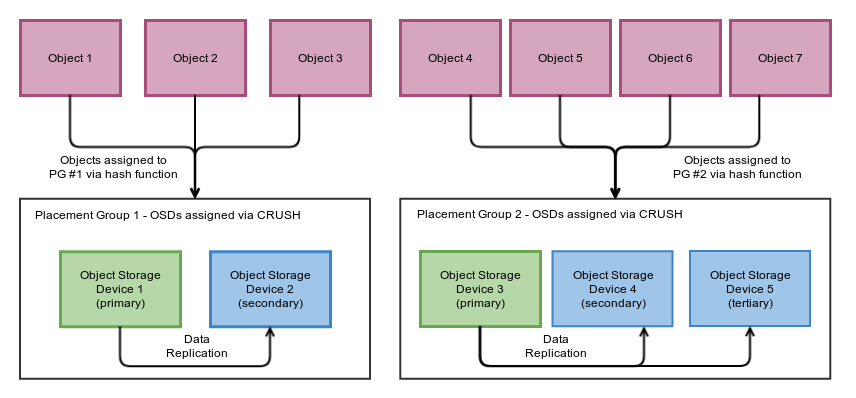
To facilitate communication and failure recovery, monitor services maintain an up-to-date representation of cluster state called the cluster map, which includes all PGs, OSDs, and other monitors. During the first interaction clients and other services have with the storage cluster, a request is sent to a monitor for the current version of the cluster map. On subsequent communications, OSDs lazily provide incremental updates of the cluster map. The RADOS paper describes how Ceph clients, OSDs, and monitors interact.
Eventual Consistency in Ceph
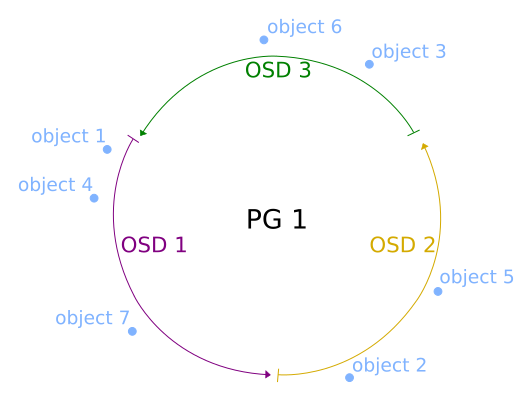
Zhang et al. describe their approach to eventual consistency in Ceph in their PROAR paper. Their replication strategy differs from standard Ceph in how it determines which OSD (i.e., which replica) receives read and write operations from clients, called primary role hash ring (PROAR). The PROAR (“primary role hash ring”) algorithm cycles through the ordered list of OSDs calculated with CRUSH, using the ID of the data object being written. For instance, if the PG replication factor is 3, and we have the object 4, then 3 % 4 = 1, thus the write operation is sent to OSD 1. This is depicted in the diagram below, adapted from Figure 3 in the PROAR paper. When the write operation is received and applied, OSD 1 immediately acknowledges the write, without waiting for acknowledgements from other replicas. Presumably, OSDs are still expected to communicate and lazily replicate data among themselves. The name “hash ring” suggests a similarity to the consistent hashing ring described in the Dynamo paper. While PROAR iterates over the OSDs circularly, CRUSH provides consistent hashing.
By distributing writes across the OSDs of a PG and acknowledging the applied write from the same OSD, PROAR improves write latency at the expense of consistency. PROAR claims to provide eventual consistency, and the fact that operations on a given object are deterministically directed to the same replica can help to ameliorate typical replication anomalies, such as stale reads.
Other eventually consistent replication strategies
The PROAR paper proposes one approach to supporting eventual consistency in Ceph. We could also consider other ways to modify the various replication strategies currently supported by RADOS. The RADOS paper describes three replication strategies: primary-copy, chain, and splay. Figure 2 from the RADOS paper is included below as a reference point. We’ll look at each of these replication strategies and consider how we might tweak them to lower write latency.
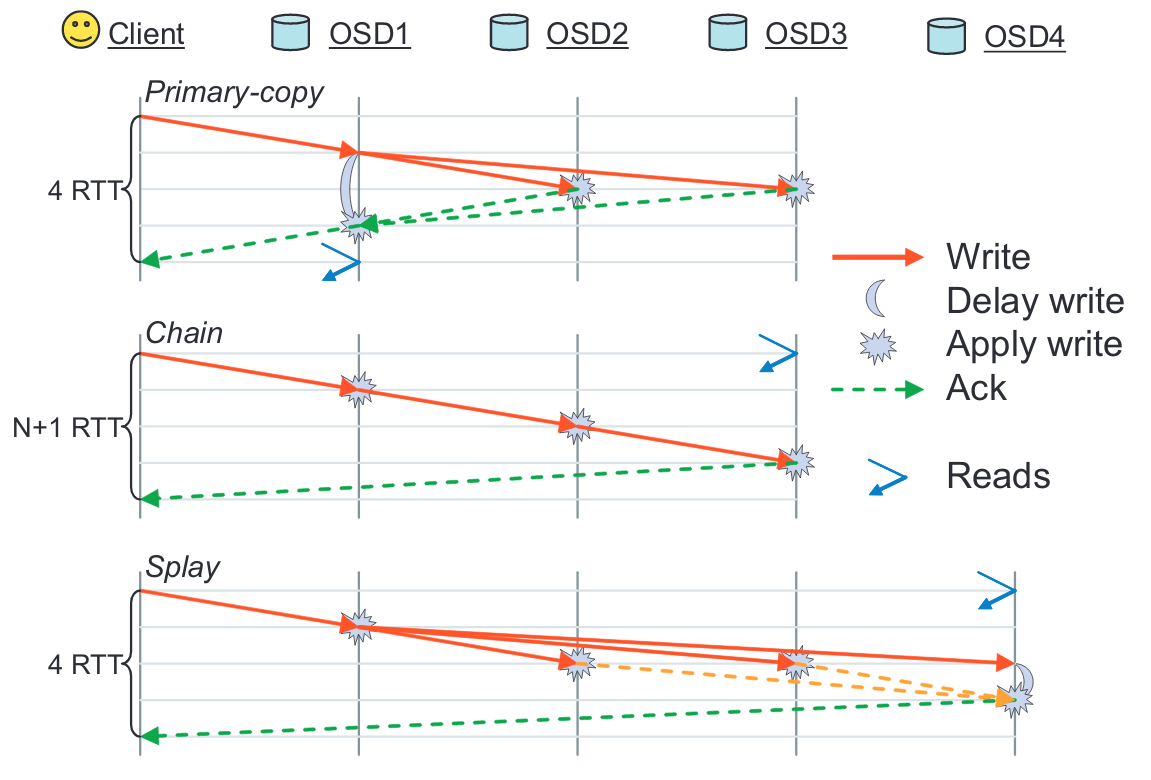
The default replication strategy for Ceph OSDs is primary-copy, in which clients are expected to send all write and read operations to the primary OSD for the PG. An acknowledgment of an applied write, or ack, is sent to the client from the primary OSD. A client only receives an ack when it is known that all replicas have received the write. This ensures strong consistency, therefore maximizing data safety, or the ability to recover data after failures. The different replication strategies have different policies for which OSD sends an ack to the client and to which OSD a client should send read operations, but in all three replication strategies, write operations are always sent to the primary OSD.
In each replication strategy that RADOS uses, write latency includes time for each replica to acknowledge a write operation. As a consequence of where read operations are directed and when the primary OSD acks to the client, read operations are always strongly consistent. In the below discussion, we consider alternative approaches that could lower write latency, including changing when a client receives an ack and which OSD to send read and write operations to. We want to continue to ensure that read operations will only observe the effects of writes that have already been applied at some OSD; we won’t allow reading of a write that has not yet been applied. However, reads may observe the effects of writes that have been applied at only one replica, or a subset of replicas, instead of all replicas.
For primary-copy replication, let’s compare the behavior of read operations between the primary OSD and secondary OSDs if we change when the primary OSD acks relative to a received read operation. Currently, the primary replica acks after a write has been applied at all replicas, thus reads return a strongly consistent value. Alternatively, we could ack once the write has been applied just at the primary. Other replicas could send an ack to the client asynchronously after applying the write. In this case, reads are strongly consistent as long as the primary is active, and weak reads occur if the primary goes down and other replicas have not received and applied all writes. This level of consistency is the same as PROAR, the difference being that all writes and reads are still funneled through the primary OSD which could have increased ack latency during times of high load.
In this weakening of the primary-copy replication strategy, an epoch for tracking which replicas have received which updates would be necessary, because we can no longer rely on the primary logically being the last to apply an update. Note that when the primary OSD fails in the standard primary-copy replication strategy, a newly elected primary OSD may not have received all writes from the former primary OSD. The same recovery process can be used for the weakened and standard primary-copy replication strategies, although recovery time for the weakened replication strategy would likely be longer. PROAR approaches failure recovery by maintaining a PG log at each OSD in the PG.
For chain replication, we consider how we can change which replica receives read operations and which replica acks to the client. Reads sent to the primary will always be strongly consistent, but will return values for writes that may not have been propagated to other replicas. Typically, reads sent to the last replica in the chain (the tail) are strongly consistent because acks are sent from the tail. If the primary replica were to ack instead of the tail, then reads sent to the tail can be, at most, n-1 versions old, assuming n updates in a row, where each OSD in the chain from the primary to the tail has a version of the data object that is at least as old as that of its predecessor. In general, if the replica that acks writes (say, OSDack) is at least as far down the chain than the replica that receives reads (OSDread), then reads are strongly consistent. Furthermore, the number of replicas in the chain between OSDread and OSDack is the “replication factor”, or the number of replicas on which each write will be applied.
Finally, we consider splay replication. The main difference between primary-copy and splay is which OSD acks to the client that a write has been applied. This allows better load balancing by splitting read and write workloads across the primary and tail replicas. This difference is considered in our above weakening of primary-copy replication. So, we observe that because the primary replica applies writes before propagation to other replicas, then to reduce latency the tail should ack concurrently while applying writes. It seems that changes to primary-copy and splay replication converge to similar protocols for which replica acks to the client, and which replica receives read operations. This is due to wanting to prevent dirty reads at the primary replica.
Bolt-on Causal Consistency
Bolt-on causal consistency, as proposed by Bailis et al., is a mechanism for upgrading the consistency guarantee provided by a datastore from eventual to causal consistency. This approach is useful for datastores such as Cassandra, which support weak and strong consistency via quorum consistency, but cannot natively support causal consistency.
Bolt-on causal consistency assumes that the underlying datastore is eventually consistent and implements a shim layer over it. This would seem to suggest that if we can support eventual consistency in Ceph, whether with the PROAR approach or with one of the other replication approaches I’ve sketched out, then we can also have causal consistency “for free” by means of the bolt-on approach. Another assumption is that the bolt-on shim layer has access to the merge function of the datastore. For instance, Bailis et al. note that the last-writer-wins merge function requires knowledge of which writes are concurrent, or do not have sequential dependence. This merge function is not implemented in Ceph, since it currently only supports strong consistency. Though it may be possible to support last-writer-wins semantics by adding a version to each object, it would result in an undesirable data overhead for applications with many objects. Another major, but straightforward, assumption is that the shim layer will be deployed with clients as well.
Finally, bolt-on assumes that reads will obey the happens-before relation, that the datastore provides single-value register semantics instead of multiple versions, and that there are no callbacks from the datastore. These assumptions all hold in Ceph: the happens-before relation is obeyed because clients deterministically send write operations to the same replica for a given object, and the weakened versions of each replication strategy do not allow dirty reads; Ceph updates objects in place, and so provides single-value register semantics; and callbacks are not present in the POSIX interface to Ceph’s subsystem.
Final Thoughts and Next Steps
It seems to me that implementing weaker consistency in Ceph can be consolidated in OSDs because of the decoupling between cluster state (maintained by the cluster map) and write replication. This means that Ceph’s monitors and use of CRUSH can provide the state of the cluster in a strongly consistent manner, without affecting the consistency level of read and write operations. The proposed weakenings above require changes to when a write is acknowledged, which replica acknowledges an applied write, or which replicas should receive read operations. These changes appear possible in specific places in the protocol, but they may affect many other aspects such as the correctness, complexity, or runtime of disaster recovery. Understanding the depths of these details is beyond the scope of this post.
Once the use of a variety of consistency models is possible in Ceph, providing tools to make development easier in a mixed-consistency environment would be nice. Language-level abstractions such as the ones I discussed in my previous post could play an important role here.